



Разработчики из Оксфордского университета создали первую в мире программу, которая распознает речь по губам на уровне целых предложений и делает это намного лучше человека. Ее работа основана на использовании нейросетей и методов глубинного обучения. Научная статья исследователей, которая была подготовлена к конференции ICLR 2017, опубликована в открытом доступе.
Автоматические системы распознавания речи на основе мимики человека имеют большой практический потенциал: они могут быть использованы для создания слуховых аппаратов нового поколения, биометрической идентификации или расследования преступлений. Поэтому ученые уже много лет пытаются разработать программу для «чтения» по губам, но до сих пор им не удавалось добиться успеха. Современные системы распознавания речи на основе мимики хорошо «считывали» отдельные слова и словосочетания, однако они не могли справиться с целыми предложениями.
Авторы нового исследования преодолели это ограничение с помощью программы LipNet, в основе которой лежит использование LSTM-нейросети. Эта нейросеть представляет собой подвид рекуррентных нейросетей, для которых характерно наличие обратной связи. Ее главная особенность заключается в том, что она способна обучаться долговременным зависимостям. На практике это означает, что LSTM-нейросеть по умолчанию хранит информацию в течение продолжительного периода времени и способна работать с контекстом в длинных предложениях (подробнее о LSTM и рекуррентных нейросетях вы можете прочитать в материале). Кроме того, исследователи также использовали специальную сверточную нейросеть (STCNN), которая хорошо справляется с задачей анализа видео, и обучение методом нейросетевой темпоральной классификации (Connectionist Temporal Classification, CTC).
В качестве исходного материала авторы работы взяли базу данных Grid, в которой было собрано более 32 тысяч видеозаписей. На них 13 человек произносили на английском языке предложения, построенные по одинаковому принципу: команда (4) + цвет (4) + предлог (4) + буква (25) + число (10) + наречие (4). В скобках указано количество вариантов слов для каждой из шести словесных категорий. Разнообразие вариантов обуславливается тем, что разные звуки (например, [p], [b], [m]) во время произношения выглядят почти одинаково, то есть имеют общую визему. Всего каждое предложение имело по 64 тысячи вариантов.
В ходе тренировки LipNet училась следить за губами говорящего на видео, и на основе этого понимать, что он сказал. Программу обучали на 88 процентах выборки, оставшиеся 12 процентов были использованы для проверки ее работы.
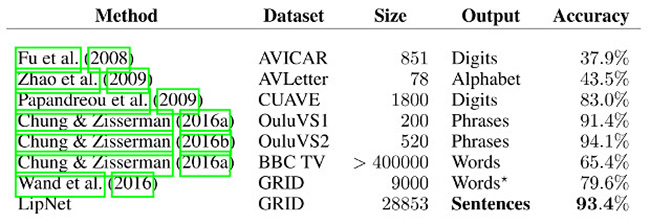
Сравнение работы LipNet с работой других программ, которые распознают буквы, слова или словосочетания
Результаты тестирования показали, что LipNet может правильно распознавать речь по губам в 93,4 процентах случаев. Таким образом, системе удалось не только обойти другие программы, но и специально обученных людей (их точность распознавания речи достигает 52,3 процентов). Тем не менее, сами авторы работы отмечают, что условия проверки работы LipNet были весьма «тепличными», при распознавании произвольной человеческой речи результат может быть значительно хуже.
Ранее компания Microsoft усовершенствовала систему распознавания устной речи, работа которой также основана на использовании сверточных и LSTM-нейросетей. Теперь система, которую планируется использовать в в голосовом помощнике Cortana, игровой приставке Xbox One и других программах, делает меньше ошибок, чем профессиональный специалист по набору текста.
Источник: N+1

















